

Why Elon Musk Imported a Power Plant
On energy as the binding constraint of the AI buildout
In 2024, xAI built the world’s largest AI training cluster in 122 days. The industry average for a project of that scale is four to six years.
Musk did it by buying a defunct Electrolux factory in Memphis, trucking in 35 portable gas turbines under a regulatory loophole, and powering 100,000 GPUs from equipment that wasn’t supposed to be there long enough to need a permit.

When the EPA closed the loophole in early 2026, he bought 41 permanent turbines and put them across the state line in Mississippi, where permitting was faster. Then five 380 MW turbines from Doosan Enerbility in Korea. None of it was enough. His team purchased a 1.2 GW power plant overseas and shipped it across an ocean.
Data center economics make the behaviour rational.
Dylan Patel of SemiAnalysis runs the unit math: an AI cloud generates roughly $11 billion in revenue per gigawatt per year. Bringing a data center online six months earlier is worth billions in net present value. At those numbers, importing a power plant is not extreme. It is maths.
Jensen Huang has been saying it for a year.
We are now a power-limited industry. He is right.
This essay is a discussion of the power limit,
The Energy Bottleneck
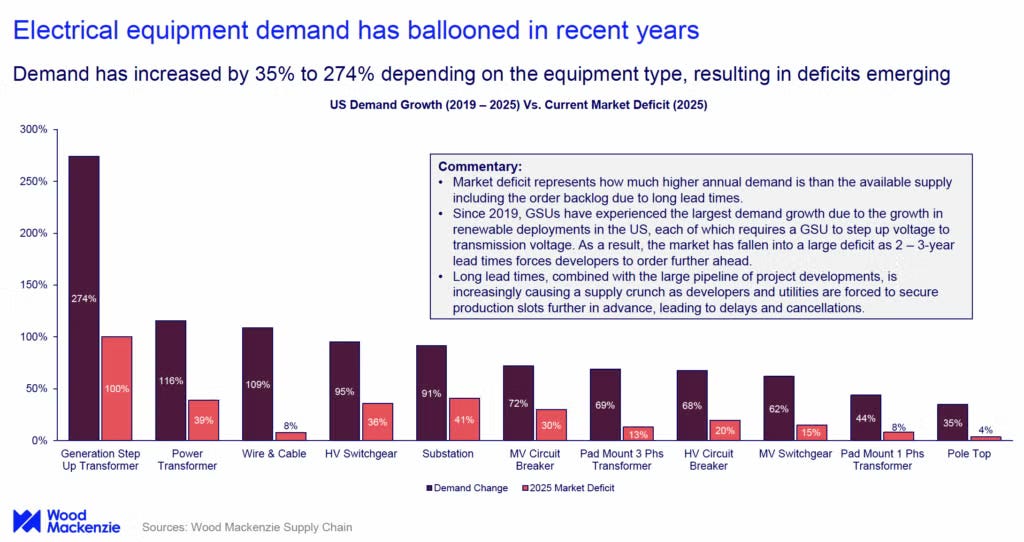
A friend who runs a credit fund forwarded me a quote sheet for a high-voltage transformer last spring. Lead time on the unit: 142 weeks. He had never seen anything like it in twenty years of looking at industrial capex.
Then last week I had coffee with a man who had been the CEO of one of the largest US CPU manufacturers, a man who’s been in the semiconductor industry since the 80’s. He said the same thing as Jensen, the constraint isn’t the chips, its power.
Hyperscaler capex in 2026 will exceed $725 billion, larger than Switzerland’s economy, and most of it is tied to campuses that need power the grid cannot deliver.
A useful anchor:
One gigawatt is the electricity consumption of about 1.8 million people. Roughly Phoenix. Or San Francisco plus Oakland combined. A 1 GW data center uses more electricity in a year than the entire state of Vermont, or Rhode Island, or Alaska.
Hyperscalers are now building these by the dozen. Meta’s Hyperion campus in Louisiana is 5 GW, the residential equivalent of 4.2 million homes, or about the population of Kentucky. Stargate Abilene came online at 1.2 GW in late 2025. xAI’s combined Colossus campuses target 2 GW. OpenAI had 1.9 GW deployed by the end of 2025; SemiAnalysis projects Anthropic crosses 5-6 GW this year.
Sam Altman’s stated long-run target is to add 52 gigawatts a year of new AI compute.
The entire U.S. peak national load is 745 GW.
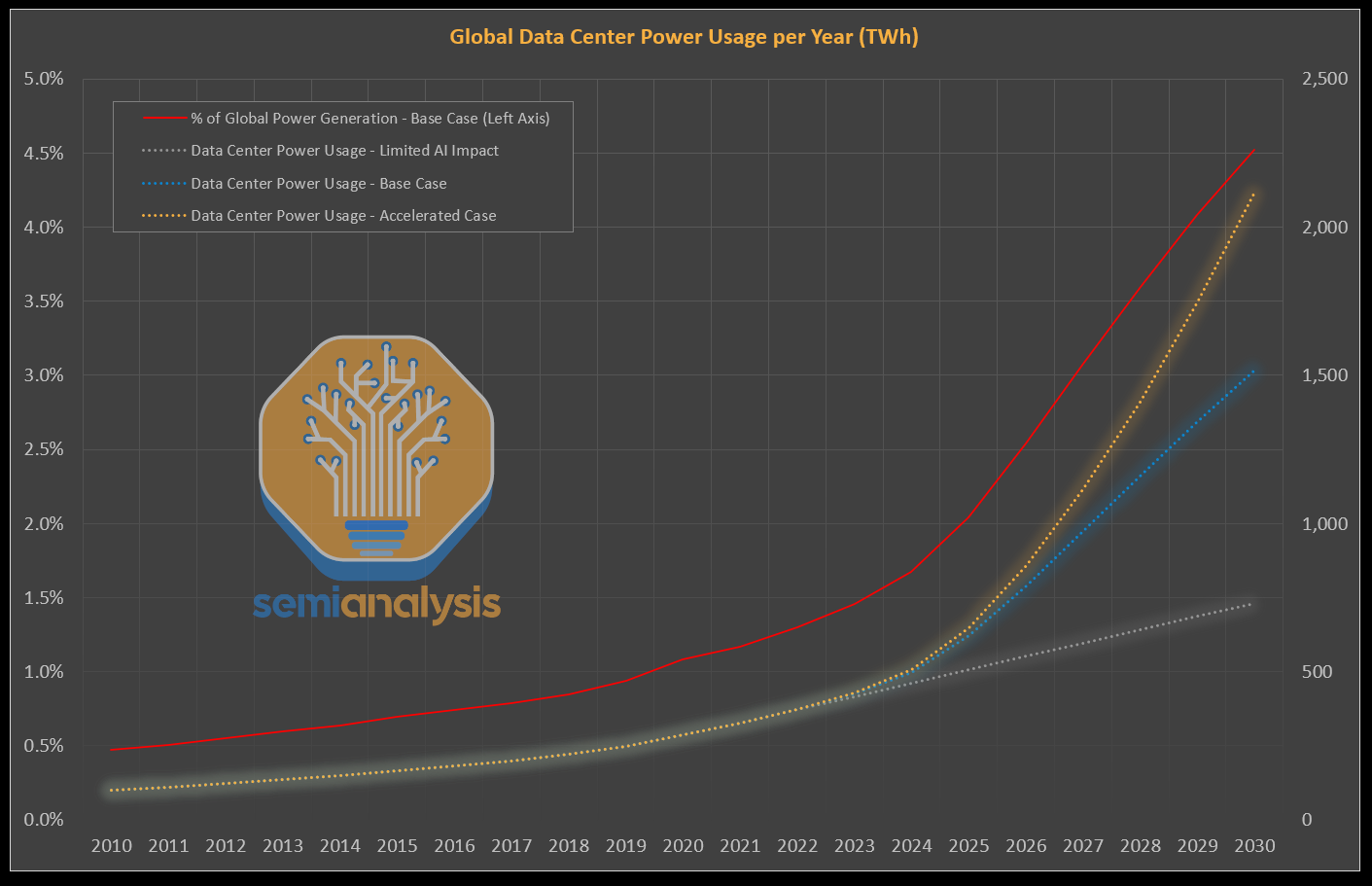
Those headline numbers are inflated, though. ERCOT has over 100 GW of large-load interconnection requests sitting in its queue, but Patel and PJM’s market monitor are explicit that the queues are filled with duplicates, hyperscalers file at multiple sites to preserve optionality, then walk away from the ones they don’t need. The real demand is probably 30-50% lower than the headline. The directional signal is unambiguous.
The supply side is messier still.
The U.S. is not actually short of energy in absolute MWh terms. It is short of deliverable energy at the right time and right place. PJM has roughly 200 GW of installed nameplate capacity, but only 145 GW of accredited capacity, power the system can rely on at peak.
The gap is intermittent renewables, retired generation still on the books, and units that can’t perform under stress. Calling this an energy shortage misses the diagnosis. It is a deliverability shortage.
The grid was built for 1-2% annual demand growth. Virginia and Texas now run at 90-95% utilization in the AI corridors. NERC’s most recent transformer lead time is 120 weeks for distribution units and 210 weeks, over four years, for large power transformers. Prices are 4-6x what they were before 2022.
PJM’s December 2025 capacity auction cleared 6,623 MW below the reliability requirement. The first time in its history the system has fallen short of the one-event-in-ten-years standard.
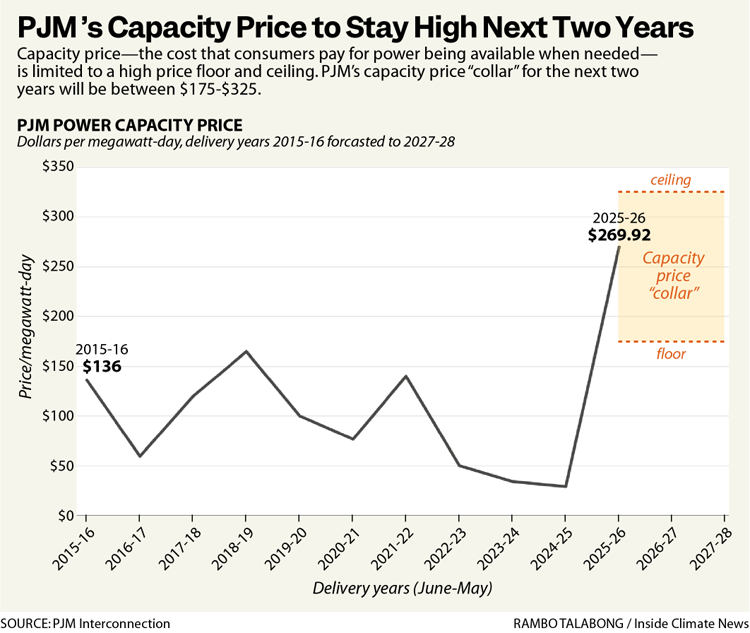
The fragility is not theoretical.
A 1.5 GW data center trip in Virginia in 2024 nearly caused rolling outages across the Eastern Interconnection. The Department of Energy was forced to issue a Section 202(c) emergency order to access roughly 35 GW of backup generation that would otherwise have been ineligible. More than half of U.S. high-voltage distribution transformers are over 33 years old.
This is what makes the energy bottleneck different from the prior ones.
CPU, HBM, and optics were engineering problems with manufacturing solutions. You build more fabs. You qualify more suppliers. You ramp the line. Power is different. You cannot build a nuclear plant in 18 months. You cannot conjure a transformer from a backlog. You cannot push 5 GW through wires that do not exist. The constraint is not a process. It is physics, permitting, and the physical world.
Brian Janous ran Microsoft’s energy strategy for twelve years before founding Cloverleaf Infrastructure. His diagnosis: nobody in the industry is worried about getting chips anymore. They are worried about being able to plug them in.
Why Now?
The shape of AI’s power demand changed in 2025.
Through the chatbot era, large models were bursty. A query came in, the GPUs lit up, the answer went out, and the cluster idled. Operators sized for the peak and lived with the slack.
Agentic AI broke that model. Agents work in the background, browsing, coding, reasoning, executing, twenty-four hours a day. The duty cycle approaches one. What used to be peaky is now baseload.
Reasoning models accelerated the curve.
A standard Google search consumes about 0.3 watt-hours. The original ChatGPT, per Sam Altman, used 0.34 Wh per query. Reasoning models — GPT-5 and equivalents — use roughly 19 Wh on a medium-length prompt, because the model generates long internal traces before producing the answer the user sees. That is fifty times the energy of a search, for a single user-visible response.
Inference is now the largest energy drain in the system, larger than training. Training a GPT-4-class model consumes around 50 GWh — enough to power San Francisco for three days. The user-facing system that runs after training consumes that much every several days, forever.
The hardware compounded the problem. A traditional enterprise rack drew 5-10 kW — roughly 5-10 homes’ worth of power. Today’s GB200 NVL72 rack draws 120 kW — about 100 homes per rack.
Nvidia’s projection is that future racks will pull a megawatt each, or a thousand homes per rack. Huang at GTC 2026: 250 MW is the current scale-up ceiling for a single fabric, with no near-term cap on how high it goes.
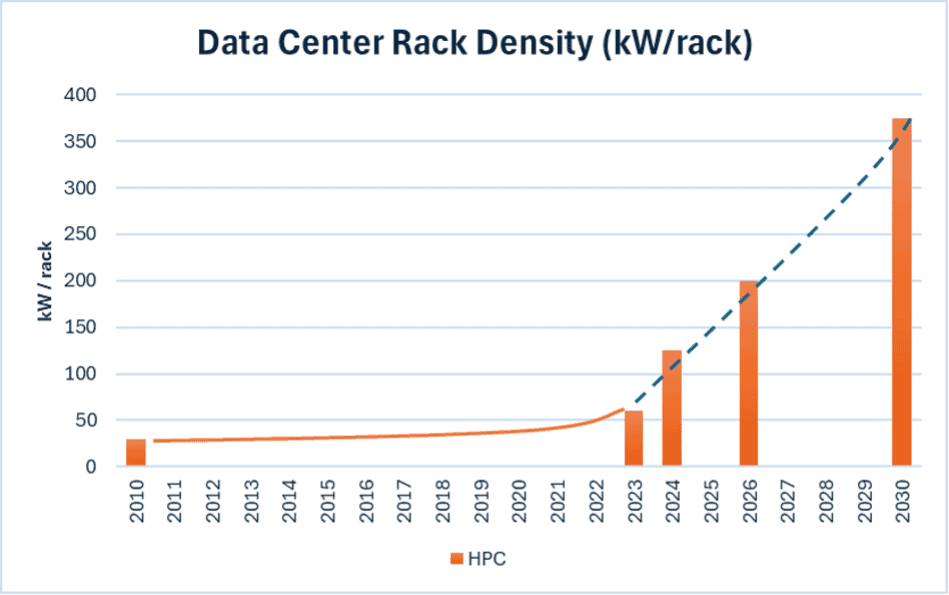
That density requires direct liquid cooling, high-voltage DC distribution, and power delivery infrastructure that traditional data centers were never built to handle. You do not retrofit your way to a 100 kW rack. You demolish and rebuild.
The Efficiency Response
Demand is exploding. Supply is constrained. The lever between them is efficiency and engineers are pulling it harder than the headlines suggest.
Three things at once.
Algorithmic efficiency. This is the underappreciated lever. AI token costs have fallen roughly 280x in two years. Mixture-of-experts routing, FP8 and FP4 quantization, distillation, speculative decoding — the model layer is moving faster than the chip layer. A frontier-quality response in early 2024 cost an order of magnitude more in compute than the equivalent today.
Hardware efficiency. Each Nvidia generation delivers 2-3x performance per watt over its predecessor. Vera Rubin is designed around tokens per watt as the primary optimization metric. Custom silicon — Google’s TPUs, Amazon’s Trainium, Meta’s MTIA — pushes further by stripping out general-purpose flexibility for specialized throughput.
Facility efficiency. Power Usage Effectiveness, or PUE, measures how much of a data center's grid draw actually reaches the servers, versus how much is lost to cooling, lighting, and power conversion. A PUE of 1.5 means for every watt the facility uses, only two-thirds reaches the chips; the rest is overhead. The industry average a decade ago was 1.8. Today's air-cooled facilities run 1.4-1.6. Liquid-cooled AI clusters hit 1.1-1.2. Full immersion gets to 1.03-1.08.
Efficiency is buying us 2-3x. Demand is growing at roughly 70% per year. Efficiency wins the battle and loses the war, but it determines who survives the squeeze. Hyperscalers with the best tokens-per-watt economics dominate the 2026-2030 cycle. The ones without get capped by their power supply contracts.
This is why Huang’s framing of AI factories as manufacturing economics matters. The metric that wins is no longer FLOPs per chip. It is tokens per watt.
Let’s dive into potential solutions.
The Near-Term Bridges
Hyperscalers are not waiting for utilities. The industry calls it speed to power, and the playbook is to bypass the grid entirely.
Gas turbines. GE Vernova’s order book is full through 2029-2030. H/J-class heavy-duty units — the right scale for a hyperscale campus — are the worst choke point. Prices have nearly tripled since 2019. GEV’s backlog crossed 100 GW this year. Every major U.S. AI campus has a GEV purchase order somewhere in the chain.
Siemens Energy carries a parallel story across the Atlantic. Backlog at $158 billion. Some turbine frames sold out for seven years. Doosan Enerbility, the Korean industrial giant, is the third major heavy-duty turbine supplier and now an unlikely AI play, courtesy of Musk.

Fuel cells. Bloom Energy is the surprise winner of 2026. Solid-oxide fuel cells deploy in 55-90 days, run on natural gas with significantly lower local emissions than turbines, and ramp cleanly with the variable loads that AI inference creates. Oracle’s pivot to up to 2.8 GW of Bloom systems for a single AI campus — replacing both turbines and diesel — is the template the rest of the industry is now studying. Bloom’s backlog has roughly doubled this year.
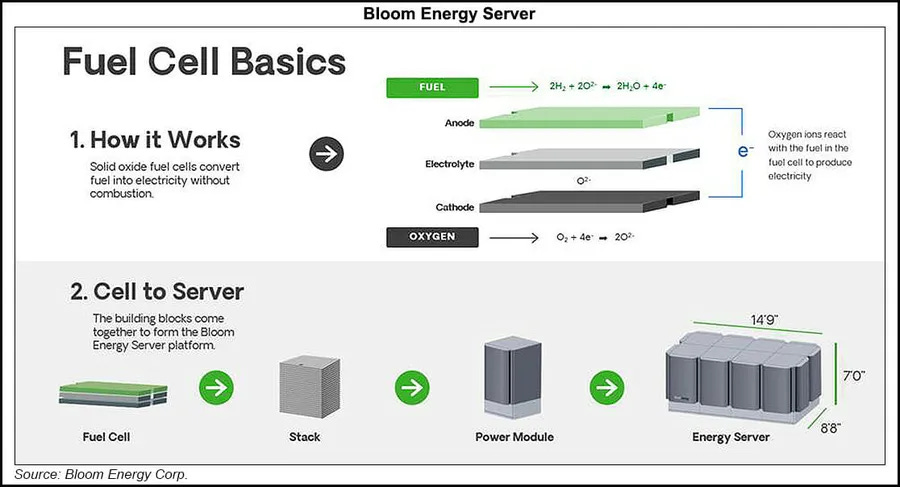
Storage and power smoothing. This is the under-covered category. Gigawatt-scale training clusters create instant power swings of tens of megawatts as GPUs sync, checkpoint, and idle in unison. Meta’s LLaMa 3 paper documented the problem; the engineering workaround was a flag literally called pytorch_no_powerplant_blowup to inject dummy workloads that smoothed the power draw. At scale, that wastes tens of millions of dollars annually. The hardware solution is batteries between the generator and the rack. Tesla Megapack dominates — Colossus runs 168 of them. Fluence Energy and Eos Energy are the public-market alternatives.

The siting layer. A new class of company sits between hyperscalers and utilities: powered-land specialists. Janous’s Cloverleaf buys land where grid headroom exists and sells it pre-permitted. Crusoe pioneered modular off-grid data centers, originally for stranded gas in oil fields, now selling AI capacity. Lancium does flexible-load contracts that get prioritized in interconnection queues. Mostly private, mostly fast-growing, all capturing margin between the hyperscalers and the utilities who cannot get out of their own way.
The Geothermal Surprise
The category nobody saw coming a year ago is geothermal, and specifically the new generation of enhanced geothermal systems that adapt fracking technology to drill artificial heat reservoirs.

The economics work for hyperscalers in a way they do not for retail utilities.
Geothermal delivers 24/7 carbon-free baseload, which is what hyperscalers need. It can be sited near data centers without grid interconnection. It scales. And it is faster than nuclear: first commercial projects come online in 2028, full scale by 2030. The Rhodium Group estimates that, sited optimally, geothermal could meet up to 64% of forecast hyperscale data center growth in the early 2030s.
The deal flow has accelerated:
Google + Fervo Energy. Google was the first hyperscaler to commit. Fervo’s Cape Station in Utah is now under development as the largest enhanced geothermal facility in the world, targeting 500 MW. Google added a 115 MW PPA in 2026. Fervo has filed to go public.
Google + Ormat Technologies. A 150 MW PPA signed in early 2026 through Nevada utility NV Energy’s Clean Transition Tariff. Ormat is the public-market incumbent for conventional geothermal and now licensing Sage Geosystems’ next-generation technology.
Meta + Sage Geosystems. 150 MW from Sage’s geopressure system, founded by a former oil and gas executive using techniques borrowed directly from fracking.
Meta + XGS Energy. Another 150 MW from a closed-loop system in New Mexico, powering Meta’s regional AI infrastructure.
Meta’s strategy is the most interesting tell. They are backing two independent geothermal approaches simultaneously. They are not waiting for a winner. They are cultivating an ecosystem of dedicated private power providers. That is the behavior of a buyer who has decided this is structurally important and is willing to pay to de-risk the supply chain.
Ormat is the only liquid public name. Fervo will be when it lists. The supporting layer — drillers, downhole equipment, geophysics services — overlaps directly with the oil-services complex. Liberty Energy, the fracking company, is already an investor in Fervo. The shale playbook is being applied to clean firm power.
The Long Game: Nuclear
For carbon-free 24/7 baseload at hyperscale today, nuclear is still the only proven answer at the gigawatt level. The hyperscalers know this. They have spent the last 18 months locking in over 10 GW of PPAs and restarts.
New builds are still 6-10 years away. Restarts are 2-4. The early money has gone to restarts.
Amazon + Talen Energy. The biggest single deal in the entire space, and the cleanest illustration of the new procurement model. Talen signed a 17-year, $18 billion PPA with AWS in mid-2025 for up to 1,920 MW from the Susquehanna nuclear plant. Full delivery by 2032. The two companies will jointly evaluate plant uprates and small modular reactors on the same site. This is not a credit purchase or an offset. It is the acquisition of physical, round-the-clock power generation, locked in for almost two decades.
Microsoft + Three Mile Island. Constellation Energy is bringing Unit 1 back online by 2028 — 835 MW dedicated exclusively to Microsoft. The optics of restarting Three Mile Island for AI compute are extraordinary, and largely uncontested.

Google + Duane Arnold. A 25-year PPA with NextEra to restart the Iowa plant by 2029. The first U.S. nuclear restart explicitly attributed to hyperscale AI demand.
Vistra is the other public-market beneficiary, with the largest competitive nuclear fleet in the U.S. and direct hyperscaler relationships across its sites.
Constellation, Vistra, and Talen sit at the center of the trade. All three trade at premiums to historical multiples. All three still appear underpriced against the duration of the contracts they are signing.
SMRs from Oklo, NuScale, and the BWX Technologies supply chain are the 2030+ story. Factory-built, co-located, modular — exactly the deployment model hyperscalers want. Execution risk is real. Timelines will slip. But the demand is locked in. Amazon and Talen are explicit about exploring SMRs at Susquehanna; Microsoft, Google, and Meta have parallel development deals with Oklo, TerraPower, and X-energy.
The fuel layer is its own bottleneck. Cameco and the broader uranium complex face a structural 85 million pound deficit. HALEU, the high-assay low-enriched uranium needed for next-generation reactors, is in genuine shortage, and Russia’s role in the supply chain has become geopolitically untenable. The setup looks like Big Oil in the early 1970s: undercapitalized, structurally short, and about to be rediscovered.
The Stack Around the Stack
Generation is half the problem. Delivery is the other half.
Cooling. Vertiv has become the Nvidia of thermal management. You cannot air-cool a 100 kW rack. Direct-to-chip liquid cooling is no longer an upgrade. It is a hardware requirement. Every new AI campus is a Vertiv campus by default.
Transformers. Every electron that reaches a data center has been stepped down through a chain of transformers — from 765,000 volts on long-distance transmission lines to the 480 volts that feed a server rack. The largest of these — the grid-scale units feeding substations — weigh 400 to 800 tons each. Heavier than a fully loaded Boeing 747. There are roughly a dozen factories on Earth that can build them, and fewer than fifty specialized rail cars in North America capable of moving them. A single unit takes 12 to 18 months to manufacture, then weeks to deliver under police escort.
This is where the lead-time crunch is most acute. Hitachi Energy committed $6 billion to expand production and hire 15,000 people, with its CEO publicly warning that utilities without existing reservations will wait up to four years. GE Vernova builds the large units that feed substations. Powell Industries — historically a Texas oil-and-gas equipment maker — booked its first data center “megaproject” order in late 2025 and has watched its backlog swell to $1.6 billion.

High-voltage distribution. The industry is moving from traditional AC distribution to 800V DC architectures inside the data center, because conversion losses at scale waste roughly 10% of incoming power as heat. That redesign reroutes spend toward Eaton, Hubbell, and the broader switchgear complex.
Construction and transmission. Quanta Services builds the transmission lines, substations, and grid hardware that connect hyperscale campuses to whatever feeds them. They are the industrial labor end of the supercycle, constrained on workforce more than backlog. Electrician wages have roughly doubled in the AI corridors over the past two years.
Secured-power assets. Crypto miners such as IREN, CIFR, and others own something genuinely scarce: pre-negotiated grid interconnections at scale, mostly in cheap-power geographies. Several have begun repurposing those sites as AI and HPC colocation. The asset is not the building or the rigs. It is the grid access agreement that nobody can replicate in under five years.
What 10x and 100x Could Look Like
Most arguments about AI infrastructure are conducted in the abstract. The numbers make them concrete.
Global AI compute deployed today is approximately 28 GW. Sam Altman has stated he wants to add 52 GW per year. Hyperscaler announced capex implies similar trajectories.
The question is what happens if user demand for tokens 10x’s, then 100x’s, from current levels.
Assume continued efficiency gains, call it a 50% reduction in energy per token from architectural improvements, despite reasoning models pushing in the opposite direction. The arithmetic is unforgiving.
A 10x in token demand requires roughly 140 GW of AI compute — five times the current installed base. Running at hyperscale utilization, that consumes about 1,050 TWh per year. That is one quarter of total current U.S. electricity generation dedicated to AI alone, or the entire annual output of Germany.
A 100x requires roughly 1,400 GW — nearly twice the current U.S. peak national load of 745 GW. To put it bluntly: 100x’ing AI demand requires the United States to construct an entirely new electricity system, of greater capacity than the existing one, dedicated to compute.
This is not a forecast. It is a constraint statement. The reason a 100x cannot happen by 2030 is not that the chips cannot ship. It is that the electrons cannot exist.
ASML can scale from 70 EUV tools per year to 100. TSMC can build more N3 capacity. Hitachi can hire its 15,000 transformer workers. None of those scale a grid. The constraint is a fifty-year-old infrastructure system that grows at 1-2% per year colliding with a workload that wants to grow at 70%.
The reason hyperscalers are signing 17-year PPAs and restarting Three Mile Island is that they have run this math. The reason xAI imported a power plant is that it ran the math first.
The Bear Case
The case I am most afraid of being wrong about is the one that took down everyone who got the prior cycle right.
Cisco saw the internet coming. They were correct about the demand. They were correct about the infrastructure required. They were correct that fiber, switches, and routers would be the picks and shovels of the next decade. Their stock lost 89% of its value in the next two years anyway. The demand projection was right. The timing was wrong. Infrastructure built ahead of demand becomes infrastructure depreciated against no revenue.
The same thing could happen here.
AI token costs have fallen 280x in two years. If they fall another 280x, through better architectures, smaller models, specialization, distillation, the demand math collapses. We don’t need a second United States grid. We need 1.3x what we already have. And the transformer makers and SMR startups and gas turbine OEMs find themselves carrying two decades of backlog against demand that did not arrive on schedule. The infrastructure is real. The numbers are real. The trade still goes to zero, because everyone modeled the same thing at the same time.
We have seen this pattern before. The railroad capex cycle of 1865 to 1893 built the physical infrastructure that powered the next century of American growth. It also bankrupted a generation of railroad operators in waves — the Panic of 1873, the depression of 1893.
The people who made money in the long run were not the ones who funded the railroads. They were the ones who owned the steel that the rails were made of, the land the rails ran through, and the banks that lent against the bonds. The picks and shovels.
Every revolution looks digital from the front and physical from the back. Software ate the world for a decade. Now the world is sending the bill, payable in concrete and copper and high-voltage steel.
One Big Carry Trade
A framework I found helpful is to think about the AI buildout as a giant carry trade.
Hyperscalers are taking electricity priced at $40-80 per megawatt hour and converting it into intelligence priced at thousands of dollars per million tokens. The structure pays as long as the spread holds. Power costs at 2-3% of per-token economics do not slow anything down. GPU depreciation is the larger cost. Power is the constraint, not the expense.
The interesting question is who captures the margin in the conversion.
In 2023-2024 the answer was Nvidia. In 2024-2026 it broadened to HBM and the foundry layer. In 2025 CPUs and optical interconnect names started to compound. In 2026 the answer rotates to the energy stack.
Four people who rarely agree on anything agree on this. Jensen Huang calls it a power-limited industry. Elon Musk calls electrical energy the limiting factor for AI. Dylan Patel calls training runs substation constrained. Brian Janous says the only thing operators worry about now is being able to plug their chips in.
The companies named in this essay sort roughly along the structural argument:
Speed-to-power. GE Vernova for turbines. Bloom Energy for fuel cells. Siemens Energy for the global equivalent. Tesla, Fluence, and Eos for the storage layer that smooths the load.
Nuclear baseload. Constellation, Vistra, and Talen for the existing fleet that hyperscalers are locking up. BWX Technologies and Cameco for the fuel and the supply chain.
Geothermal as the surprise pillar. Ormat as the public incumbent. Fervo when it lists. Sage Geosystems and XGS as the next-generation platforms.
The transformer and switchgear crunch. Hitachi Energy. Powell Industries. Eaton and Hubbell across the broader power-distribution complex.
The thermal layer. Vertiv as the dominant cooling and rack-power name.
Adjacent and indirect. Quanta Services for grid construction. Cloverleaf and Crusoe in the powered-land siting layer. IREN and Cipher for repurposed crypto interconnections. Copper through Freeport.
Optionality further out. Oklo, NuScale, and the SMR cohort for the 2028+ deployment cycle.
The political risk — water, emissions, ratepayer revolt — is real, but it does not change the math. It lengthens queues, which raises the value of permitted assets.
The most aggressive operators are already running the optionality. SpaceX and xAI filed for one million orbital data center satellites in early 2026, the explicit pitch is putting compute where electricity is essentially free and cooling is solved by physics.
That is a 2030+ story at best, and roughly 3x more expensive per watt than terrestrial today. But it is on the roadmap. When the constraint is hard enough, the responses get strange.
In 2019 you could order a high-voltage transformer and have it within a year. Today the queue runs 80-130 weeks. The orders keep coming.

Because the shortage now is not about energy. It was about deliverable energy, in the right place, at the right time.
The frontier model will not be the binding constraint anymore.
The transformer is.
This is the fourth essay in a series on the AI compute stack, after The Other AI Trade on CPUs as the orchestration layer, Half of Nvidia on HBM, and Six Billion Dollars of Light on optical interconnects. Together the four pieces map the supply chain that turns capital into compute.
Disclaimer
This essay is for informational and educational purposes only. It does not constitute investment, legal, tax, or financial advice and should not be relied upon as such. Companies and securities discussed are referenced for analytical context; nothing in this essay is a recommendation to buy, sell, or hold any security. The author may hold long or short positions in some of the companies mentioned. Markets are uncertain, forecasts are imperfect, and past performance does not predict future results. Readers should conduct their own research and consult qualified professionals before making any investment decision.
Companies Mentioned
Power generation: GE Vernova (GEV), Siemens Energy (ENR.DE / SMNEY), Bloom Energy (BE), Constellation Energy (CEG), Vistra Corp (VST), Talen Energy (TLN), NextEra Energy (NEE), Ormat Technologies (ORA), Oklo (OKLO), NuScale Power (SMR), BWX Technologies (BWXT), Doosan Enerbility (KS: 034020).
Equipment & infrastructure: Vertiv (VRT), Eaton (ETN), Hubbell (HUBB), Powell Industries (POWL), Quanta Services (PWR), Hitachi Energy (parent: Hitachi, 6501.T).
Storage & power smoothing: Tesla (TSLA), Fluence Energy (FLNC), Eos Energy (EOSE).
Fuel & materials: Cameco (CCJ), Freeport-McMoRan (FCX), Liberty Energy (LBRT).
Secured-power assets: IREN (IREN), Cipher Mining (CIFR).
Hyperscalers and AI labs (referenced as buyers, not investment recommendations): NVIDIA (NVDA), Microsoft (MSFT), Amazon (AMZN), Alphabet (GOOGL), Meta Platforms (META), Oracle (ORCL), AMD (AMD).
Private companies referenced: xAI, OpenAI, Anthropic, Fervo Energy (S-1 filed), Sage Geosystems, XGS Energy, TerraPower, X-energy, Crusoe, Cloverleaf Infrastructure, Lancium, Starcloud, SpaceX.
Further Reading
SemiAnalysis — Dylan Patel and team’s industry research at newsletter.semianalysis.com. The canonical source for AI infrastructure and data center power. Their Datacenter Industry Model and Energy Model are the data layer behind much of this essay.
Dylan Patel on the Dwarkesh Podcast (March 2026) — three hours on the logic, memory, and power bottlenecks. The single best long-form interview on the binding constraints of the buildout.
Rhodium Group — “Beyond the Megawatts: Geothermal Energy’s Potential to Power Data Centers” (2025). The 64% number that anchors the geothermal section.
IEA — “Energy and AI” Special Report (2025). The official institutional projection.
PJM Interconnection — capacity auction results and market monitor reports at pjm.com. The price data behind The Bill Arrives section.
Cloverleaf Infrastructure — Brian Janous’s various podcast appearances, particularly the Catalyst and Build, Repeat episodes. The operator’s view on grid integration.
Nice. I know nothing about Bloom. Always considered it a shitco. Is it cost competitive?
How will the all in cost to compute compare to China's.